
一、union的基本定义
Union的中文叫法又被称为共用体、联合或者联合体。它的定义方式与结构体相同,但意义却与结构体完全不同。下面是union的定义格式:
union 共用体名
{
成员列表
}共用体变量名;
它与结构体的定义方式相同,但区别在于共用体中的成员的起始地址都是相同的,而结构体中的成员则具有各自的地址。
下面,我们通过一个struct与union的嵌套来说明两者的区别所在:
struct my_elem
{
int type;
union my_info
{
char*str;
int number;
}value;
}elem_t;
访问方式与结构体相同,例如,要访问number变量,可以以如下的方式进行访问:
elem_t.value.number = 10;
Union和struct的区别是共用体中的成员的起始地址都是一样的,而结构体中的成员都具有各自的地址。以下是Elem_t在内存中的存储示意图。

看到变量在内存中的存储位置之后,也就明白了union的特性了。共用体的好处在于,程序中能够使用不同类型的变量并且只占用一个变量的存储空间,从而节省存储空间。
在上述程序中,共用体的两个成员所占的存储空间大小一样,都是四个字节,因此这个共用体所占存储空间的大小就是四个字节。如果共用体的成员的存储空间大小不一样,那么共用体存储空间的大小取决于成员中存储空间最大的一个。

二、union的应用场景
1、数据打包 :灵活转换数组和数据
我们平时会遇到一些数字传感器,往往他转换完成后的数据需要2 个字节或者4 个字节来存储,比如陀螺仪的3 轴 加速度的三个寄存器都是16bit 的,但是我们通过IIC 或者SPI 读取的时候都是一个字节一个字节的读取的。这时候我们就可以使用联合体来进行数据的大包转换。
union
{
unsigned char ary[6];
struct
{
unsigned short X;
unsigned short Y;
unsigned short Z;
}Data;
}acc_t;
// 在SPI读取函数中按单字节给数组赋值
acc_t.ary[0] = 0x21;
acc_t.ary[1] = 0x43;
我们在 SPI 的读取程序中给联合体的数组赋值后,可以直接使用 Data 来获取到 short 类型的传感器输出值。
printf("The X is:0x%x\n",acc_t.Data.X);
输出为:
The X is:0x4321
这说明联合不需要额外的赋值和强制类型转换,同一个数据可解释为两个不一样的东西。
在使用联合在打包数据的时候,必须要清楚当前处理器是大端对齐还是小端对齐。
- 大端对齐:数据的低位保存在内存的高地址中,数据的高位保存的内存的低地址中。
- 小端对齐:数据的低位保存在内存的低地址中,数据的高位保存在内存的高地址中。
下面用图的形式举一个例子分别在大端对齐和小端对齐中的存储形式。
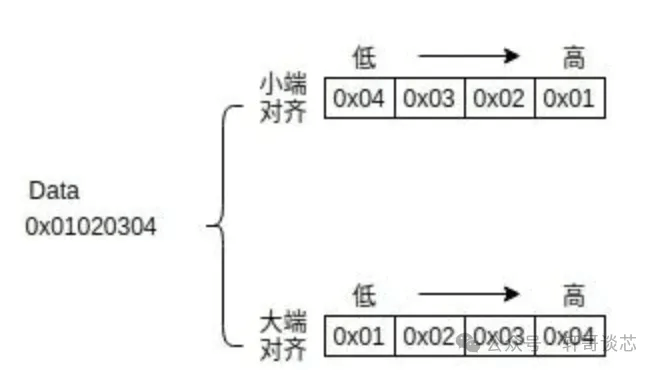
有了大端对齐和小端对齐的认知下,我们来看 union 如何对数据进行打包,下面给出一段代码:
int main(void) {
// 定义一个联合体
union ByteSplit {
unsigned int word;
unsigned char byte[4];
} data;
// 给联合体的字节成员赋值
data.byte[0] = 0x11;
data.byte[1] = 0x22;
data.byte[2] = 0x33;
data.byte[3] = 0x44;
// 输出整数和字节
printf("整数值为:%u\n", data.word);
return 0;
}
上述的运行结果会根据对齐方式的不一样而有所差别。如果是小端模式:
整数值为:0x44332211
如果是大端模式:
整数值为:0x11223344
TIP:当然,采用这种方式进行数据的打包存在一定弊端,因为处理器的对齐方式不同会产生不同的结果。因此,通常我们会采用数据移位的方式来实现:
char byte1 = 0x21;
char byte2 = 0x43;
short word;
word = (((short)byte2) << 8)|((short)byte1);
上述的写法便不会收到处理器对齐方式的影响,也具有更好地移植性。
2、空间利用:减少变量占用空间
在大多数编程环境中,union 通常用于空间优化。由于 union 的所有成员共享同一块内存空间,因此可以通过使用不同的数据类型来优化内存使用。以下是一个例子:
union Data {
int i;
short s[2];
char c[4];
};
union Data data;
data.i = 12345;
printf("The short values are: %hd, %hd\n", data.s[0], data.s[1]);
printf("The char values are: %d, %d, %d, %d\n", data.c[0], data.c[1], data.c[2], data.c[3]);
在这个例子中,我们使用一个 union 来存储一个 int 值,在另外一个时间段,我们也可以使用这个 union 的其他成员(short 和 char 数组)来进行数据存取。
需要注意的是,虽然这种方法可以节省内存,但是它可能会导致数据不一致。例如,如果先使用 char 数组来读取数据,然后再使用 int 成员来读取数据,那么 int 成员将不会包含正确的值,因为它的数据已经通过 char 数组被修改了。因此,在使用 union 时,需要确保对数据的访问顺序是正确的。
这里我们举一个 CANopen的例子。
在Canopen 中,我们有一种PDO的通信形式,他就相当于预定义好了一条CAN 帧中 8 个自己的数据意义。我们可以简单的理解为,不同的 CANID,已经定义好了数据的具体意义,比如ID:1 和ID:2 的8 个字节分别表示成4 个速度变量和四个温度变量。
分析:在上面的背景当中,我们得知发送的消息的时候并不是同时要发送速度,温度的,而是每个帧分开来的发送的,并不是同时需要,那这个时候,我们就可以采用 union 的特性来构造一个数据结构,这样做的好处是能够缩减变量占用的内存。
struct buffer
{
short id; /*CAN——ID*/
union
{
struct
{
short speed1;
short speed2;
short speed3;
short speed4;
} speed;
struct
{
short temp1;
short temp2;
short temp3;
short temp4;
} temp;
}Info;
}my_buff;
采用上述的结构的话,我们可以计算一下,结构体占用的存储空间是 10个字节,如果我们分别为温度和速度的解析来定义缓存变量,那么占用的内存空间将几乎增大一倍。
这里有了 id的加入,我们可以在接收端对数据进行解析了。
通过上述的这个例子可以了解,如果不使用 union 的话,在进行数据传输的时候,直接将由 struct 构造的数据形成数据帧发送过去,发送的数据包要比使用 union 构造的数据大不少,使用 union 构造数据,既能够帮助我们节省了存储空间,还节省了通信时的带宽。
3、数据解析:直观面对数据
上面一个例子我们使用 union 在数据传输中优化了代码,那么 union 在数据解析中又具有什么作用呢,看下面这样一段代码:
typedef union
{
char buffer[10];
struct
{
char len;
char CMD;
char payload[7];
char crc;
}fields;
}pack_t;
void packet_handler(pack_t* packet)
{
if(packet->fields.size > TOO_BIG)
{
//错误
}
if(packet->fields.cmd == CMD)
{
//处理对应的数据
}
if(packet->fields.payload[0] == 0x01)
{
//具体处理数据
}
}
要理解这个数据解析过程,需要用到 union 中的成员存放在同一个地址这个特性,buffer[10]中的元素与 fields 中的元素是一一对应的,用一张图来表示就很清楚了,如下图所示:

看了这张图,我想就很清楚了,往 buffer 里写了数据,直接从 fileds 里面读出来就可以了。
三、总结
在C语言中,联合体(union)是一种特殊的数据类型,它允许多个变量共享同一块内存空间。这种特性使得联合体在某些场景下非常有用,特别是在优化代码和数据解析方面。
在数据传输中,联合体可以用来优化代码,减少内存占用和通信带宽。通过将多个相关变量合并到一个联合体中,可以节省存储空间,从而减少数据传输所需的带宽。
联合体在数据解析方面也非常有用。通过将数据打包到一个联合体中,可以方便地解析数据。例如,可以将数据包解包为一个联合体,然后直接从联合体中读取数据,而无需进行复杂的数据结构转换。
总之,联合体在C语言中是一种非常有用的数据类型,它可以在许多场景中优化代码和数据解析,提高程序的性能和可读性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...
